Random "work in progress" shots
category: general [glöplog]


if you ain't redlining, you ain't headlining
Quote:
Love those 2d gears as well!Numtek: cool. I always liked hexagons. Used them in Altparty invitation years ago too ( https://vimeo.com/1464225 ) :)
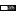
63-134 fps depending on the number of rays

this bilinearly interpolates quads of 8x8 in size. Actually 4x4 will look much smoother and converge towards 63 fps during the rendering. With no adaptive subsampling the fps are around ~32, which is not acceptable.
this bilinearly interpolates quads of 8x8 in size. Actually 4x4 will look much smoother and converge towards 63 fps during the rendering. With no adaptive subsampling the fps are around ~32, which is not acceptable.

Rudi cool wip's! What is the platform btw?

deepr: PC Windows: softrender C++, (no d3d, no opengl, no hw-shaders, no polygons)


Playing with pathtracing in shadertoy. I think I've found a set of materials that complement each other nicely.
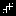
@yx That's one of the best gold materials I've seen.


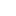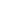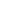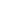
Sneak peek to the upcoming Epoch demo



@noby, that looks like my "satori style" demo in 32 bytes, don't make me release it :D

:)))
this is a quick visit with some archived song exports from my side




@msqrt: I seriously need to know what you're attempting there. :)

@fizzer, it’s an adaptive meshing scheme driven to the limit; the leaf geometry are approximately pixel-sized oriented disks that face the camera. The implementation recursively checks if a certain voxel needs to be refined or if small enough, rasterized (just an atomicMin to a z-buffer image) or if the sdf guarantees that it will be empty. The recursion is realized via a work stack where work is pushed into and read from, this visualization shows a deliberate stack overflow :)
This is related to the Reyes discussions we had, I’m yet to get the stochastic raster working but this method gives pretty OK performance for supersampled primary visibility — and no depth discontinuities etc. like you would in raymarching. The visibility sampling and SDF recursion depth are separate, the next step would be to shade the disks and then plot but that requires 64bit atomics or a workaround hack with the rasterizer.
Another thing to try is to see if this is faster for just standard marching cubes for large resolutions; the SDF is sampled very sparsely compared to those.
This is related to the Reyes discussions we had, I’m yet to get the stochastic raster working but this method gives pretty OK performance for supersampled primary visibility — and no depth discontinuities etc. like you would in raymarching. The visibility sampling and SDF recursion depth are separate, the next step would be to shade the disks and then plot but that requires 64bit atomics or a workaround hack with the rasterizer.
Another thing to try is to see if this is faster for just standard marching cubes for large resolutions; the SDF is sampled very sparsely compared to those.
That's really awesome! I've recently been discovering the power of atomic pixel-plotting myself and I'm really impressed by how many I can push through while still staying fast.
What would be really cool is if you can implement a hierarchical depth buffer and cull whole nodes of your tree by testing against conservative depth bounds. I also see that you don't have backfacing culling yet - I've found this to actually provide a real performance improvement even if it's just one conditional directly controlling one atomic operation.
In regard to 64-bit atomics, I discovered that they are somehow available on NVIDIA hardware but I haven't yet figured out how to actually use them, because they seem to require the use of some other NVIDIA-specific memory objects and it's not obvious how to create and manage them.
What would be really cool is if you can implement a hierarchical depth buffer and cull whole nodes of your tree by testing against conservative depth bounds. I also see that you don't have backfacing culling yet - I've found this to actually provide a real performance improvement even if it's just one conditional directly controlling one atomic operation.
In regard to 64-bit atomics, I discovered that they are somehow available on NVIDIA hardware but I haven't yet figured out how to actually use them, because they seem to require the use of some other NVIDIA-specific memory objects and it's not obvious how to create and manage them.
I was referring to this of course: https://www.khronos.org/registry/OpenGL/extensions/NV/NV_shader_atomic_int64.txt
Backface culling can only be done in the lowest stage (otherwise we risk culling fine detail due to aliasing in the sampling) and in this case requires computing a gradient before plotting which will be somewhat expensive — I already tried moving the splats towards the exact intersection using the gradient. I’ll try adding the backface cull too, though the recursion seems to be the limiting factor here until we hit quite high sample counts. A hierarchical depth cull might be very effective since we can (and do) traverse the implicit tree in a z-first order, have to think about it and test it out. Thanks for the idea!
Yeah, I’d rather not go NV only so another possibility would be to simply have a list of splats that gets pushed to and rasterize as a separate pass. Might help with execution coherency, though now we can hide a lot of the plotting work into the latency of the recursion.
Yeah, I’d rather not go NV only so another possibility would be to simply have a list of splats that gets pushed to and rasterize as a separate pass. Might help with execution coherency, though now we can hide a lot of the plotting work into the latency of the recursion.
@yx: cool path-tracing!
Quote:
Sneak peek to the upcoming Epoch demo
I was hoping to see this at Simulaatio... :(
But luckily the entry was awesome anyway!