
sound processing - extract a repeated sample
category: music [glöplog]
Hi everybody,
Lets say i have a soundtrack. Inside, i have a sample that is repeated several times (a voice for example). The sound repeated is exactly the same, but each time with a different musical background (instruments or noise).
if i want to extract that sound (in this case the voice without the instruments), is there any technique, or tool that allows me to do that (based on the fact the sample is repeated several times)?
tecnique i was thinking :
1) find where the patterns are repeated and move each of them in separate samples
2) synchronise these samples (so they start at exactly at the same time and are the same length
3) run some algorythm that extract only what is similar to all samples. dont know if the algorythm will work on wave directly or on frequencies (after fft)
maybe this is a well know technique and this is possible to do with basic sound processing programs (like goldwave or audacity). they are lots of musicians here on pouet maybe there is some that can help.
Lets say i have a soundtrack. Inside, i have a sample that is repeated several times (a voice for example). The sound repeated is exactly the same, but each time with a different musical background (instruments or noise).
if i want to extract that sound (in this case the voice without the instruments), is there any technique, or tool that allows me to do that (based on the fact the sample is repeated several times)?
tecnique i was thinking :
1) find where the patterns are repeated and move each of them in separate samples
2) synchronise these samples (so they start at exactly at the same time and are the same length
3) run some algorythm that extract only what is similar to all samples. dont know if the algorythm will work on wave directly or on frequencies (after fft)
maybe this is a well know technique and this is possible to do with basic sound processing programs (like goldwave or audacity). they are lots of musicians here on pouet maybe there is some that can help.

Sounds like a derivate of http://en.wikipedia.org/wiki/Longest_common_substring_problem
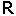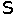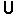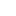
Maybe a set of fourier transformations of the repeated parts can be processed in some way in order to extract the sample?

Sounds like a typical case for noise-reduction, doesn't it? Use the repeating sample as a noiseprint, use it to remove it from the original, then inverse the new sample with the old one and keep the results. Basically like when people create acapella-tracks.
Of course, the final quality will suck.
Of course, the final quality will suck.

If you did 1) and 2) and the sample is *really* identical (this is important!), you could try this. I'm assuming you have two samples for now, but it might also work for more.
3) Convert both samples to mono.
4) Subtract one sample from the other. In a wave editor, this can be done by inverting the phase of one sample and mixpasting it with the other. You should hear both samples WITHOUT the common part now.
5) Now, mixpaste both original mono samples (not inverted). Now subtract the result from 4) from this mix and you should more or less get the original sample you want.
3) Convert both samples to mono.
4) Subtract one sample from the other. In a wave editor, this can be done by inverting the phase of one sample and mixpasting it with the other. You should hear both samples WITHOUT the common part now.
5) Now, mixpaste both original mono samples (not inverted). Now subtract the result from 4) from this mix and you should more or less get the original sample you want.
Oh, and I actually think you have to one invert the sample which you inverted in step 4 also in step 5 again, before mixpasting them.
-one
@Saga: In theory that works perfectly, but you have a problem here with the framerate, the chance that you can _exactly_ allign the two samples is low, they'll always be a bit out of the wanted phase.
I tried it out once, and it does work, but you'll still hear the uncommon parts of the song faintly through it. if you can get those silent enough (be sure to put a gate on it) you'll be fine.
I tried it out once, and it does work, but you'll still hear the uncommon parts of the song faintly through it. if you can get those silent enough (be sure to put a gate on it) you'll be fine.

saga: That's what I said (badly, apparently). The idea is that the noiseprint would have to work as one of the phase opposites.
thx all for ur answers. i was just thinking the same as whynot2000 : aligning the two soundsample perfectly would be almost impossible.
i should try lord graga noise reduction technique, but it wont work for more than 2 samples
i should try lord graga noise reduction technique, but it wont work for more than 2 samples
check the concepts of cross-correlation and auto-correlation, in time or frequency domain.
I was thinking roughly the same as saga, but with FFT data instead of the actual samples. Might help reduce the need to get them perfectly aligned.

psonice: That's what I have been trying to get across too, but apparently I suck at explaining things today. :)
Without any idea of what you want to achieve, another thing that might cause problems is if there's processing applied on the mix as a whole (aka "mastering").
Even if the sample used is identical, the small variations of [everything else] would result in the samples being technically identical. This means that the result after the phaseflip will not be totally clean.
If it weren't for this, getting a cappellas from singles with instrumental version would be a breeze (but it isn't).
Even if the sample used is identical, the small variations of [everything else] would result in the samples being technically identical. This means that the result after the phaseflip will not be totally clean.
If it weren't for this, getting a cappellas from singles with instrumental version would be a breeze (but it isn't).
gloom: re-reading what you said, yeah I see it now.. well, I do almost zero audio stuff, so I've no idea how noise cancellation is normally done, or what a noiseprint is. I'm guessing that would have made some sense to anyone doing audio stuff :)
FFT doesn't really help you much in reducing alignment constraints; subtraction in the frequency domain is exactly the same as subtraction in the time domain (DFT/FFT is a linear transformation).
As Navis says, the best bet for alignment is probably finding the point with maximum cross-correlation between the two samples. And of course, what lug00ber said.
There are also techniques for lead voice/instrument extraction that use the background music as a cue — basically the algorithm “learns” (via PCA and some sort of supervised learning) what components the instruments sound like, and then can use that to filter them out from the final mix. I'd guess this is overkill for what you're trying to achieve, though :-)
As Navis says, the best bet for alignment is probably finding the point with maximum cross-correlation between the two samples. And of course, what lug00ber said.
There are also techniques for lead voice/instrument extraction that use the background music as a cue — basically the algorithm “learns” (via PCA and some sort of supervised learning) what components the instruments sound like, and then can use that to filter them out from the final mix. I'd guess this is overkill for what you're trying to achieve, though :-)
Auto-correlation might get you the length of the sample (a peak). Or a look at the waveform.
If the sampler plays the sample exactly the same way (a) then split the soundtrack based on this length and _add_ these parts.
Ideally the voice will get a 6dB boost and the uncorrelated rest approximately a 3dB boost.
Note that the precondition (a) is unlikely to happen.
If the sampler plays the sample exactly the same way (a) then split the soundtrack based on this length and _add_ these parts.
Ideally the voice will get a 6dB boost and the uncorrelated rest approximately a 3dB boost.
Note that the precondition (a) is unlikely to happen.

#ponce: Are you confusing autocorrelation with crosscorrelation? Autocorrelation is correlating one sample with itself, and by definition the peak will always be at A(0).
Sorry, the correct symbol is R_xx(0).
Nope.
I used it once for BPM detection and you have to ignore the base peak (ie, assuming a maximum possible BPM). Same problem here.
I used it once for BPM detection and you have to ignore the base peak (ie, assuming a maximum possible BPM). Same problem here.
Ok, so the autocorrelation of the entire song — fair enough, if the two samples are indeed in the same track.
On second thought, it might be more straightforward to just hand-pick the samples and add them by hand.
This looks nice: http://www.unmixingstation.com/
This one is free: http://www.elevayta.net/azuifgeh.htm
This one is free: http://www.elevayta.net/azuifgeh.htm

Melodyne can separate sources too with quite impressive results.
#ponce: Is it really as impressive as in the demo videos? I sort of always thought it was suspicious that they only did demos with one instrument at a time — and an acoustic guitar at that, about the simplest possible instrument to work with audio-wise.