
Raymarching Beginners' Thread
category: code [glöplog]
Marching.
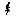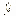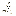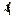
Speaking of trigonometric functions...
Code:
; use NASM/YASM
global fastsinrc
global fastsin
fcsinx3 dq -0.16666
fcsinx5 dq 0.0083143
fcsinx7 dq -0.00018542
fcpi_2 dd 1.5707963267948966192313216916398
fc1p5pi dd 4.7123889803846898576939650749193
fc2pi dd 6.28318530717958647692528676655901
fastsinrc: ; fast sinus with range check
fld dword [fc2pi] ; <2pi> <x>
fxch st1 ; <x> <2pi>
fprem ; <x'> <2pi>
fxch st1 ; <2pi> <x'>
fstp st0 ; <x'>
fld1 ; <1> <x>
fldz ; <0> <1> <x>
fsub st0, st1 ; <mul> <1> <x>
fldpi ; <sub> <mul> <1> <x>
fld dword [fcpi_2] ; <pi/2> <sub> <mul> <1> <x>
fcomi st0, st4
fstp st0 ; <sub> <mul> <1> <x>
fldz ; <0> <sub> <mul> <1> <x>
fxch st1 ; <sub> <0> <mul> <1> <x>
fcmovnb st0, st1 ; <sub'> <0> <mul> <1> <x>
fxch st1 ; <0> <sub'> <mul> <1> <x>
fstp st0 ; <sub'> <mul> <1> <x>
fxch st1 ; <mul> <sub'> <1> <x>
fcmovnb st0, st2 ; <mul'> <sub'> <1> <x>
fld dword [fc1p5pi] ; <1.5pi> <mul'> <sub'> <1> <x>
fcomi st0, st4
fstp st0 ; <mul'> <sub'> <1> <x>
fld dword [fc2pi] ; <2pi> <mul'> <sub'> <1> <x>
fxch st1 ; <mul'> <2pi> <sub'> <1> <x>
fcmovb st0, st3 ; <mul''> <2pi> <sub'> <1> <x>
fxch st2 ; <sub'> <2pi> <mul''> <1> <x>
fcmovb st0, st1 ; <sub''> <2pi> <mul''> <1> <x>
fsubp st4, st0 ; <2pi> <mul''> <1> <x-sub>
fstp st0 ; <mul''> <1> <x-sub>
fmulp st2, st0 ; <1> <mul(x-sub)>
fstp st0 ; <mul(x-sub)>
fastsin: ; fast sinus approximation (st0 -> st0) from -pi/2 to pi/2, about -80dB error, should be ok
fld st0 ; <x> <x>
fmul st0, st1 ; <x²> <x>
fld qword [fcsinx7] ; <c> <x²> <x>
fmul st0, st1 ; <cx²> <x²> <x>
fadd qword [fcsinx5] ; <b+cx²> <x²> <x>
fmul st0, st1 ; <x²(b+cx²)> <x²> <x>
fadd qword [fcsinx3] ; <a+x²(b+cx²)> <x²> <x>
fmulp st1, st0 ; <x²(a+x²(b+cx²)> <x>
fld1 ; <1> <x²(a+x²(b+cx²)> <x>
faddp st1, st0 ; <1+x²(a+x²(b+cx²)> <x>
fmulp st1, st0 ; <x(1+x²(a+x²(b+cx²))>
ret

t21: the YELLOW cube? One of us needs a test for colour blindness (or more sleep) :D
That's looking cool btw. What kind of speed/resolution are you getting with pure raytrace? And is your method suitable for GPU implementation?
That's looking cool btw. What kind of speed/resolution are you getting with pure raytrace? And is your method suitable for GPU implementation?

Intrinsics?

W s W: haha, he looks a bit drunk.

las and others: Thanks for all the hints. IQ's frameworks are great, could compile and run them without any problem. I couldn't find Ferris 4k frame, any link ?
A small beginners data type confusion question: As far as I see IQ is using the standard GLSL data types like float and vec2 etc. I see you are using e.g. float2 etc. After some google-ing I found a paper that says that NVidia came up with that and it's actually same as vec2 etc., there's even more like float3x3 instead of mat3 etc., true ? Seems there's not 'one' standard, there's lots of confusing additions...okay...time to read lots of docs now and trying implement it in the framework :-)
A small beginners data type confusion question: As far as I see IQ is using the standard GLSL data types like float and vec2 etc. I see you are using e.g. float2 etc. After some google-ing I found a paper that says that NVidia came up with that and it's actually same as vec2 etc., there's even more like float3x3 instead of mat3 etc., true ? Seems there's not 'one' standard, there's lots of confusing additions...okay...time to read lots of docs now and trying implement it in the framework :-)

I am using HLSL in that example - if you see floatN(1,1,1) that's HLSL (DirectX) - if you see vecN(1.,1.,1.) - that's GLSL (OpenGL) ;)
You might want to use HLSL if you target Win-Only platforms.
One of my fav quotes from another pouet thread:
This might not be 100% the truth about DX/GL... Try yourself and find out what fits your purpose best.
You might want to use HLSL if you target Win-Only platforms.
One of my fav quotes from another pouet thread:
Quote:
opengl -> in five minutes you get a smiling rotating cube. five days from now and you'll hate the entire humanity.
directx -> in five minutes you have nothing more than hundreds of angry com instances, absurd structures, nameless enumerators and so on. five days from now you'll make a demo.
This might not be 100% the truth about DX/GL... Try yourself and find out what fits your purpose best.

The little yellow dots on the floor are also raymarched,
nonetheless you are right in saying that I needed more sleep :)
I just coudn't stop playing around with all those magical distance functions.
I dont have hard numbers, but for that scene ,replacing the raymarched cubes with spheres more than double the performance. So ~15fps at 640x480.
To get this running on a GPU, the most involved step would be reworking the recursive octree traversal.
I might give this a try at some point, but the cpu only method is fast enough for my experiments and make it very easy to debug.
I do use SSE2 intrinsics, but not in a packet tracing manner.
So its all Vec3 stuff.
Thanks kb_, do you have in an intrinsic format (or plain C)?
Here is what I use for arc cosine:
nonetheless you are right in saying that I needed more sleep :)
I just coudn't stop playing around with all those magical distance functions.
I dont have hard numbers, but for that scene ,replacing the raymarched cubes with spheres more than double the performance. So ~15fps at 640x480.
To get this running on a GPU, the most involved step would be reworking the recursive octree traversal.
I might give this a try at some point, but the cpu only method is fast enough for my experiments and make it very easy to debug.
I do use SSE2 intrinsics, but not in a packet tracing manner.
So its all Vec3 stuff.
Thanks kb_, do you have in an intrinsic format (or plain C)?
Here is what I use for arc cosine:
Code:
__inline float arccos(const float x) {
float n = 1;
if(x < 0) n = -1;
float v = ::abs(x);
float ret = -0.0187293f;
ret *= v;
ret += 0.0742610f;
ret *= v;
ret -= 0.2121144f;
ret *= v;
ret += 1.5707288f;
ret = PI_2_f - sqrt(1.0f - v)*ret;
return PI_2_f - (ret * n);
}
T21: does your raymarcher involve any adaptive subsampling?
rudi: its brute force, one primary ray instantiated per screen pixel traversing an octree (and bouncing around/generating shadow rays).
If I where to accelerate what I have, I would keep an acceleration tree for secondary/shadow rays, but I would use another acceleration structure for the primary.
Most likely sort the bounding volume front to back, then bin them using a quad tree of the view volume.
The slab would be at a multiple of 8 screen pixel on the projection plane, this would make it clean to invoke a SIMD intersection function.
If I where to accelerate what I have, I would keep an acceleration tree for secondary/shadow rays, but I would use another acceleration structure for the primary.
Most likely sort the bounding volume front to back, then bin them using a quad tree of the view volume.
The slab would be at a multiple of 8 screen pixel on the projection plane, this would make it clean to invoke a SIMD intersection function.
I might have gotten the question wrong...
The raymarching part is simply adding a plain raymarching loop as part of the primitive intersection code.
Raytracing
raytracing + Raymarching (Now the sphere is a 'cubes' or whatever)
The raymarching part is simply adding a plain raymarching loop as part of the primitive intersection code.
Raytracing
Code:
... inside the sphere intersection
if(B < D) { // Inside
distance = B + D;
return -1;
} else { // Outside
distanceZ = B - D;
return 1;
}
raytracing + Raymarching (Now the sphere is a 'cubes' or whatever)
Code:
if(B < D) { // Inside
distance = B + D;
if(RayMarching(ray.origin-m_center, ray.direction, D)) {
distance += D;
return -1;
}
return 0;
} else { // Outside
distance = B - D;
if(RayMarching((ray.origin+ ray.direction*distance)-m_center, ray.direction, D)) {
distance += D;
return 1;
}
return 0;
}
never done octrees before. i wonder if that is faster. if not you can integrate that in. and interpolating when you know the points/pixels that you trace.
Spatial subdivision is needed when a scene usually include more then ~8 objects.
I think their is a few papers on that, and octree (specially using regular subdivision) are not the fastest...
But I picked to implement an octree because its the simplest that I know :)
The Ravi-Demo definitely benefit from this interpolating method. (but the reflection look 'filtered')
I think their is a few papers on that, and octree (specially using regular subdivision) are not the fastest...
But I picked to implement an octree because its the simplest that I know :)
The Ravi-Demo definitely benefit from this interpolating method. (but the reflection look 'filtered')
T21, on which device do you plan to implement spacial subdivision? Is it a CPU or a GPU?
The optimal "structure" depends on which computing device you intend to use i think. A BIH may perform slighly less efficiently on a GPU than a CPU and may not bring the expected performance improvements (provided you get any).
For 4-8 objects on a GPU, i'd bruteforce.. Just my 2 cents. :) 16-32 objects may benefit from the optimisations presented in this original sphere tracing paper (zeno.pdf) 20 years ago.
Above 100 items then i agree that spacial subdivision schemes start to be interresting :)
The optimal "structure" depends on which computing device you intend to use i think. A BIH may perform slighly less efficiently on a GPU than a CPU and may not bring the expected performance improvements (provided you get any).
For 4-8 objects on a GPU, i'd bruteforce.. Just my 2 cents. :) 16-32 objects may benefit from the optimisations presented in this original sphere tracing paper (zeno.pdf) 20 years ago.
Above 100 items then i agree that spacial subdivision schemes start to be interresting :)

actually, BIH performs pretty well on the GPU.. simply use persistent threads (if using CUDA) and/or speculative traversal if needed (i.e. depending on the hardware gen you are targetting)..

BIH property sound good on paper, I will have to look at the traversal logic.
So far I'm all CPU. What I'm trying to figure out mainly is a way to take advantage of AVX when I upgrade my computer later this year.
SSE2 was kind of ok handling Vec3, but with AVX its a total wast.
For image processing its a.ok , but with code that got so much conditional and 'bounce' all over the place... not thrilled.
So far I'm all CPU. What I'm trying to figure out mainly is a way to take advantage of AVX when I upgrade my computer later this year.
SSE2 was kind of ok handling Vec3, but with AVX its a total wast.
For image processing its a.ok , but with code that got so much conditional and 'bounce' all over the place... not thrilled.
Bah, for all my interest in raytracing/raymarching on iOS devices, somebody beat me to it, and I just saw an app called Ray-marching on the app store: http://itunes.apple.com/us/app/ray-marching-lite/id448282477?mt=8. Looking at the screenshots, I'd say they're doing it wrong :)
Regarding many objects and spatial subdivision, here's a small teaser from my solskogen entry runnning ~20fps (720p) on the lappy...


Psycho: nice! How is the text represented as [S]DF?

Some project we are currently working on at university - it's not realtime - but not too slow.
Some project we are currently working on at university - it's not realtime - but not too slow.
A list of parametrized primitives - curve segments and skewed lines. Looks like 39 primitives in that particular text - more is no problem (as long as they are spread out on the screen).
It's running on the compute shader in groups of 16x16 pixels, and at first each thread(/pixel) starts raymarching a primitive each and puts in on the active list (in group shared memory on chip) for the tile/group if it's close enough for any pixel in the group to hit the primitive (of course there need to be a fixed distance too, to enable AO samples).
That leaves us with just a few primitives pr tile which each thread can then raymarch normally (together with the static part of the scene) for it's own pixel.
Generally very much like modern dx11 deferred lighting schemes.
Performance wise it's important to only have a few kind of primitives (otherwise the first part of the shader will take a long time due to simd issues). So this kind of onepass solution is not suitable for figuring out which part of a very complex function is relevant for which tiles on screen.
It's running on the compute shader in groups of 16x16 pixels, and at first each thread(/pixel) starts raymarching a primitive each and puts in on the active list (in group shared memory on chip) for the tile/group if it's close enough for any pixel in the group to hit the primitive (of course there need to be a fixed distance too, to enable AO samples).
That leaves us with just a few primitives pr tile which each thread can then raymarch normally (together with the static part of the scene) for it's own pixel.
Generally very much like modern dx11 deferred lighting schemes.
Performance wise it's important to only have a few kind of primitives (otherwise the first part of the shader will take a long time due to simd issues). So this kind of onepass solution is not suitable for figuring out which part of a very complex function is relevant for which tiles on screen.
I did raymarched material in UDK just for sake of it http://i.imgur.com/yvtx7.png. What do you think should it be? I was thinking about beautiful box of smoke.

las: No caustics and shitty Monte Carlo makes Cornell a dull boy. :( Also, where's the light source!?

las : photon mapping ?
{kind=link}
psycho: what's happening at the edges? Looks like some kind of outline rendering going on. Some kind of magic iteration darkening?
Las: Looks pretty nice. You just need 10x more rays to smooth out that noise :D To fix the missing light source, just draw a white square on the top side of the cube btw.
Las: Looks pretty nice. You just need 10x more rays to smooth out that noise :D To fix the missing light source, just draw a white square on the top side of the cube btw.