
Interpolation in adaptive sub-sampling?
category: general [glöplog]
GLITCHILICIOUS
CrossProduct: haha, yea. i was actually thinking about something like that :D

Quote:
rydi: For me it looks like you still have some subdivision issues - there should be no visible hard subdivision edge near specular reflection (this 32x32 square 1/2 radius above sphere center). Also it will be good idea to always subdivide if the shadowed/unshadowed status of corners don't match (this way you'll get non-blocky shadow edge).
sure there are some issues with this. it doesnt work as i espect it to.
ive implemented the uv status matching code. because it looks blocky where the reflections are (since im working on that too). ill do the same with the shadows. i hoped that i could do this only once so that this kind of thing was adaptive with everything that dont match, but it seems i have to do this individually first.
like crossproduct says. gotta be amazing when animated realtime!
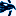
wow. something magical just happened:

its so fun too look at the shadows now :D
its so fun too look at the shadows now :D
read my post again :) at some point you will see that you are checking a lot of different criteria about when to subdivide. and then it will be way nicer to think about the whole thing as one hash... but you are getting there, nice to see.
another important thing is to think about what you really need to keep in memory: only one line of "biggest block size". When that is done, swap it's last line to be the first one of the new block line. This keeps memory and cache usage really low.
Also on the old subdivide edges vs. blocks: Check on edges, always evaluate center if any corners mismatch, interpolate edges if they match.
another important thing is to think about what you really need to keep in memory: only one line of "biggest block size". When that is done, swap it's last line to be the first one of the new block line. This keeps memory and cache usage really low.
Also on the old subdivide edges vs. blocks: Check on edges, always evaluate center if any corners mismatch, interpolate edges if they match.

shiva: yea. i think i have a hash now that works, except for the cache. ill work on that. thanks for the tip! :)
Just did this (since yesterday) to test my new Core i7:

concept proven, Core i7's are good toys :D
concept proven, Core i7's are good toys :D
for completeness, here's the quad-rendered version:

xTr1m: thats awesome. is it software rendered?
Yes, all CPU using SSE and 8 threads parallely.
it would probably go almost as fast if you deleted all the complex subsampling and interpolation code and just brute forced the thing on your 8 threads...

It most surely won't. Raytracing still takes longer than rendering those quads/pixels with OpenGL. I'm only tracing 18-20% of all pixels. Without adaptive subsampling it'd take 5 times longer.
Dunno about that - for that scene complexity on an i7, your framerate seems really slow so you must be doing something suboptimally. Check out this fully raytraced pinball game for example: http://ompf.org/forum/viewtopic.php?f=8&t=1367
ector: arauna is not a simple one-day-project where a guy hacked stuff together for the fun of it. it is not a good idea to compare pears and apples right? arauna features stuff like BVH which I am sure is quite foreign to most of the folk here.

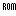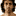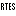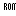
texel: your example seems to be only spheres, just adding the code for arbitrary primitives adds overhead.
anyway, 60fps at this res with such a cpu is not that impressive. there is a lot to optimize. and at some point you can just start with 1x1 blocks and subdivide for really nice aa on fast cpus! it is a very fun and visual algorithm still, teaching a lot about "compute only what you need" - and that it is not always trivial to figure that out!
and now to make this post useful...
two very simple optimization tricks that many first raytracers miss:
- compute 2d bounding boxes for all primitives, and limit your first hit tests to those
- use a shadow cache.. if pixel i-1 was shadowed by object a, test for shadowing by object a first
anyway, 60fps at this res with such a cpu is not that impressive. there is a lot to optimize. and at some point you can just start with 1x1 blocks and subdivide for really nice aa on fast cpus! it is a very fun and visual algorithm still, teaching a lot about "compute only what you need" - and that it is not always trivial to figure that out!
and now to make this post useful...
two very simple optimization tricks that many first raytracers miss:
- compute 2d bounding boxes for all primitives, and limit your first hit tests to those
- use a shadow cache.. if pixel i-1 was shadowed by object a, test for shadowing by object a first
for the shadow cache, make sure not to use a global but a thread local variable, either on the thread stack somewhere or a real __thread variable, otherwise your threads will stomp all over each other and lose most of the benefit..
i now have a structure that is 72 bits. ill try decompress it to 64 in a while but it starts to get a little tricky. i have uv-coordinates that are shorts, but texture gets strange artifacts when i reduce them to 8 bits per coord and i dont find out where it gets fuzzy.
then about the struct, i tried to pad it but it didnt seem to run any faster. anyway is hitting the cache diffictult when there are so many conditionals in the subsampler and recursion?
then about the struct, i tried to pad it but it didnt seem to run any faster. anyway is hitting the cache diffictult when there are so many conditionals in the subsampler and recursion?
rydi: good luck "decompressing" 72 bits into 64 bits :P
Quote:
it would probably go almost as fast if you deleted all the complex subsampling and interpolation code and just brute forced the thing on your 8 threads...
I second Ector. Texel, Arauna is pretty fast, much more impressive than http://pouet.net/prod.php?which=27041 for sure. You know this, modern raytracers manage hundred of millions of polys in realtime in 8 to 16 cores in realtime, so a twenty sphere scene is pretty much a joke (experiments from 2006), although demosceners still get impressed by it. I absolutely think that screen subsampling, at least at this big level, is a bad idea and waste of time/processing power. Raytracers are fast today because of memory coherence (yes, raytracers today are memory bound, not computation bound!!), so as soon as you move from reflective spheres to _real_ raytracing (say, meshes like Arauna or any other modern raytracer, subsampling will destroy this coherence. Of course, you can see MLRTA like a way of complex subsampling, but even that never proved to be more than a 15% speed benefit and only in some scenes.
iq has the leading. This is the very reason I am sick of seeing spheres, sure shading costs a lot but seriously, how about moving on? How about actually getting to somewhere decent with this whole raytracing / raymarching affair. Heaven 7 was released in 2000 and since then we just keep thinking how cool it is that we can get AA'd spheres reflecting each other with no tissue, texture; and that crappy hard edged shadows that real world would laugh with its ass at are "impressive".
Don't be funny, no offense to anyone but if any of the pictures posted in this thread as a result looks "impressive" to you I am afraid your knowledge of the things developing in the graphics industry isn't more than the knowledge you had when H7 was released (= when I was 10).
Get over it. Move on. I hope at least I can finish this stuff on time for the targeted party…
Don't be funny, no offense to anyone but if any of the pictures posted in this thread as a result looks "impressive" to you I am afraid your knowledge of the things developing in the graphics industry isn't more than the knowledge you had when H7 was released (= when I was 10).
Get over it. Move on. I hope at least I can finish this stuff on time for the targeted party…
Jezus christ man.
Let this guy do his thing.
Go join the taliban or something.
Let this guy do his thing.
Go join the taliban or something.

Quote:
I am sick of seeing spheres
harsh words from someone who just won ASM using those :P

yeah because that was the best we could do then, but we know when the horse is dead for good :).
oh well at least gargaj in PM has a damn valid point that I beg your excuse and shut the fuck up now :P. have fun if you think raytraced spheres reflecting each other are fun, but they are not for me no more.
oh well at least gargaj in PM has a damn valid point that I beg your excuse and shut the fuck up now :P. have fun if you think raytraced spheres reflecting each other are fun, but they are not for me no more.