
Interpolation in adaptive sub-sampling?
category: general [glöplog]
I worked on a raytracer for a few weeks but got issues related to speed of course. i knew heaven7/exceed allready used a technique, but wasn't sure what the technique was called. i found the description on the h7 website and found it was called adaptive sub-sampling, so i searched the web and found another website explaining it a littlebit more in detail. it did not however explain what type of interpolation technique one should use.
I've implemented a "adaptive" sub-sampler that works in theory, but the interpolation get all wrong which i think is due to linear-interpolation or bilinear-interpolation. is this the wrong interpolation or should i use something like tri-linear or cubic. the later two i have little knowledge of, but will learn em if they are relevant to the problem.
also to make sure you see what causes my problem i'll give a screenshot of three spheres which are used by this technique. initial gridsize in the shot is 32x32 and reduced to smaller sizes when sampling.

sure its quite obvious this is the wrong interpolation if one is out after what i think of, so how should one go around this problem without reducing the gridsize of the sub-sampler? is there a way or is it just me wishfull thinking?
I've implemented a "adaptive" sub-sampler that works in theory, but the interpolation get all wrong which i think is due to linear-interpolation or bilinear-interpolation. is this the wrong interpolation or should i use something like tri-linear or cubic. the later two i have little knowledge of, but will learn em if they are relevant to the problem.
also to make sure you see what causes my problem i'll give a screenshot of three spheres which are used by this technique. initial gridsize in the shot is 32x32 and reduced to smaller sizes when sampling.
sure its quite obvious this is the wrong interpolation if one is out after what i think of, so how should one go around this problem without reducing the gridsize of the sub-sampler? is there a way or is it just me wishfull thinking?

Well I can't really tell much, but from what I see on the picture, your adaptive sub-sampling implementation lacks the sub-sampling part :P. In other words, to me it looks like you are not properly sub-sampling down to 1x1 when the changes in the four corners of the sampled area are considerable. This might mean that your threshold for a "change" is actually too small or your algorithm is implemented wrongly.
I can't tell much without seeing an actual piece of pseudo or not code.
I can't tell much without seeing an actual piece of pseudo or not code.

Oh dear, I hope you didn't learn from the treezebees site :P
H7's site explains it as well as it needs to be, including the criteria for which you subdivide the squares. Bilinear should work just fine. Just be sure to sample down based on object hit differences, shadow state differences, and too great of specular differences. Interpolate the rest (u/v, color, meh).
Furthermore, 8x8 squares should be used. 32x32 is cool for machines in the early 90's though :P
H7's site explains it as well as it needs to be, including the criteria for which you subdivide the squares. Bilinear should work just fine. Just be sure to sample down based on object hit differences, shadow state differences, and too great of specular differences. Interpolate the rest (u/v, color, meh).
Furthermore, 8x8 squares should be used. 32x32 is cool for machines in the early 90's though :P
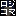
The interpolation seams ok, the treshold seams not.
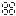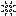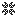
Quote:
The interpolation seams ok, the treshold seams not.

Ferris: treezebees? no. i read that one page article from h7 as i stated in the introduction. i did found out that i didnt interpolate the normals, which was a stupid mistake, and are rather obvious when i think about it. it works almost okay now. its just some minor issues. the subdivision i know worked because i tested the algorithm without interpolation which of course is slow, but just to test it was right. im guessing there will be other issues as well, but ill work on the first ones first.
what do you mean by threshold?
you know you need some sort of a difference value while comparing the shittiest derivative between two color values. in other words, it's a simple color triplet via which you decide that the color values are not close enough on the corners and further sub-sampling is necessary.
something like:
here Color(...) is the threshold value.
something like:
Code:
Color topLeft ...;
Color topRight ...;
if (topRight - topLeft > Color(...))
subSample();
here Color(...) is the threshold value.
obviously a unified (hypotenuse within RGB space) value for comparison would make much more sense. mine was a simple pseudo example.
You could use the luminance value, computing it from the RGB triplet.

I think treating every square independently is the wrong way to go. You're probably better off focusing on the edges of the squares, since that's where you're getting those artefacts.
Here's an idea:
- Sample all points in 32x32 grid
- This gives you a great big island of 32x32 squares with accurately shaded corners
- Sample the centre point on each 32-pixel edge
- Compare those centre points to what would be the interpolated results
- Note where the difference is above some threshold
- Subdivide all 32x32 squares that touch one or more of those edges
- This gives you some islands of 16x16 squares with accurately shaded corners
- Sample the centre point on each 16-pixel edge that not on the edge of an island
- Compare those centre points to what would be the interpolated results
- Note where the difference is above some threshold
- Subdivide all 16x16 squares that touch one or more of those edges
- This gives you some islands of 8x8 squares with accurately shaded corners
- etc.
This should avoid the situation where the edges of a 16x16 region align poorly with a neighbouring 32x32 region (or whatever) because of interpolation errors.
Here's an idea:
- Sample all points in 32x32 grid
- This gives you a great big island of 32x32 squares with accurately shaded corners
- Sample the centre point on each 32-pixel edge
- Compare those centre points to what would be the interpolated results
- Note where the difference is above some threshold
- Subdivide all 32x32 squares that touch one or more of those edges
- This gives you some islands of 16x16 squares with accurately shaded corners
- Sample the centre point on each 16-pixel edge that not on the edge of an island
- Compare those centre points to what would be the interpolated results
- Note where the difference is above some threshold
- Subdivide all 16x16 squares that touch one or more of those edges
- This gives you some islands of 8x8 squares with accurately shaded corners
- etc.
This should avoid the situation where the edges of a 16x16 region align poorly with a neighbouring 32x32 region (or whatever) because of interpolation errors.

doom: thanks alot for the usefull information! and the rest as well.
by sampling the centre point do you mean tracing the points or just the interpolation? (prolly is obvious?) :P i still dont understand that threshold thingy yet. i need to get into it in more detail. since its late here now, i need to reflect more on it tomorrow. but i really get the overall idea! thanks again!
by sampling the centre point do you mean tracing the points or just the interpolation? (prolly is obvious?) :P i still dont understand that threshold thingy yet. i need to get into it in more detail. since its late here now, i need to reflect more on it tomorrow. but i really get the overall idea! thanks again!
threshold i "limit" or "barrier". The condition, when you need to subdivide your quads, depends on the difference between the colors of the neighbors. If the difference is low, you don't subdivide. If the difference is high (the limit or the barrier or the threshold is reached), you subdivide.
Try lowering your threshold :)
Try lowering your threshold :)
having done adaptive subsampling myself (search fresnel intros) here is the trick:
the descision when to subdivide a square needs to be done based on some kind of hash. every shaded pixel returns one. this hash might include:
- color (top bits)
- which object was hit (ids are good, pointers also work)
- what recursion level
- texture coordinates
- texture id or pointer
and all of that mushed together in 32 or 64 bits. like, shift left for recursion level of hit etc.
the better your hash, the less artefacts.
also render blocks as texid/uv/addcolor/mulcolor and only fall back to plain color if that does not work at the lowest level.
the descision when to subdivide a square needs to be done based on some kind of hash. every shaded pixel returns one. this hash might include:
- color (top bits)
- which object was hit (ids are good, pointers also work)
- what recursion level
- texture coordinates
- texture id or pointer
and all of that mushed together in 32 or 64 bits. like, shift left for recursion level of hit etc.
the better your hash, the less artefacts.
also render blocks as texid/uv/addcolor/mulcolor and only fall back to plain color if that does not work at the lowest level.

Code:
render(w, h, xstep, ystep) {
axis = xstep<=ystep;
if (xstep+ystep>threshold) { bruteforce }
pic = render(w, h, xstep*(axis+1), ystep*(2-axis));
for (y = 1-axis; y<h+1-axis; y+=2-axis) for (x = axis; x<w-axis; x+=axis+1) {
p1 = &pic(x-axis,y+1-axis)
p2 = &pic(x+axis,y-1+axis)
if p1.path != p2.path {
if (p1.has_something_difficult)
pic(x,y) = trace_a_known_path(x, y, p1.path)
else
pic(x,y) = heck_just_interpolate_the_shit(p1, p2)
} else {
pic(x,y) = trace(x, y, scene)
}
}
return pic;
}
rydi: By "sampling" i mean doing the raytracing for a pixel, as opposed to interpolating the result.
okay!
shiva: i saw the fresnel intros a number of times back in those days. they where impressive, still is :p. optimization like what you are talking about should come in second hand for me because i dont have positive experiences with em. i should try get the algorithm working before being that hardcore :D or else i might not get the algo working at all :P
my code is quite a mess right now (which is me in a nutshell), thats why i didnt provide pseudo-code of my own work. i also use two buffers for the grids, one that contains offset positions in the tracer + some ray-info and another which is incremented linearly which contains positions of the grid corners + some ray-info. so perhaps i should merge these two and clean up a littlebit.
doom: okay, good thats what i imagined.
might take some time to digest all of these suggestions and find the one solution that works for me. hopefully ill be back when i stumble upon problems :p
shiva: i saw the fresnel intros a number of times back in those days. they where impressive, still is :p. optimization like what you are talking about should come in second hand for me because i dont have positive experiences with em. i should try get the algorithm working before being that hardcore :D or else i might not get the algo working at all :P
my code is quite a mess right now (which is me in a nutshell), thats why i didnt provide pseudo-code of my own work. i also use two buffers for the grids, one that contains offset positions in the tracer + some ray-info and another which is incremented linearly which contains positions of the grid corners + some ray-info. so perhaps i should merge these two and clean up a littlebit.
doom: okay, good thats what i imagined.
might take some time to digest all of these suggestions and find the one solution that works for me. hopefully ill be back when i stumble upon problems :p
well, today you don't need adaptive sampling you know, CPUs are fast, you can render 3d models very quickly (not to speak of simple sphere/planes). With SSE you can raytrace four pixels in one go, and with multithreading you simply linearly scale the performance.
In case you are playing with real raytracing (polygon models instead of reflective spheres) I think subsampling will not perform especially well, as raytracers need high ray coherence to work well.
In case you are playing with real raytracing (polygon models instead of reflective spheres) I think subsampling will not perform especially well, as raytracers need high ray coherence to work well.
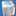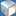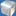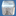
iq: im not that smart :)
if you use hardware rendering, don't do what software renderers (like afaik h7) did. there's no reason for disconnected vertices because the gpu can quickly render arbitrarily shaped poligons.
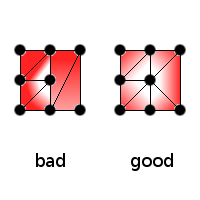
this will explain many of the artifacts you see. if tesselate like this and you decrease max. size to 16x16, you probably won't need to subsample on specular highlight intensity changes.
this will explain many of the artifacts you see. if tesselate like this and you decrease max. size to 16x16, you probably won't need to subsample on specular highlight intensity changes.
Ger: im not using hardware-rendering.
well. here's what i got so far:

top pics contain original subdivision (rays) which are the black dots.
bottom pic contain original subdivision plus the centre-point on each edge which are the green dots. so far so good?
well. here's what i got so far:
top pics contain original subdivision (rays) which are the black dots.
bottom pic contain original subdivision plus the centre-point on each edge which are the green dots. so far so good?
Quote:
im not using hardware-rendering.
you are wasting your time :P. sorry.
Decipher: hey, i am doing this for fun and educational purposes. :) not because its easier to do draw polygons and use hardware-pipeline.
Decipher: anyway.. treezebees site is down, and there is no way i can get hold of that intro they did.
or article for that matter.