
Raymarching Beginners' Thread
category: code [glöplog]
what do you guy advice to buy as CG (that have plenty of pixel shaders horse power). some GTX 680 or is there better ATI alternative ?

At work I have a 660 GTX, 580 GTX at home. Still kicking!
If you want OpenGL 4.3 - you have to go for NVIDIA.
If you want OpenGL 4.3 - you have to go for NVIDIA.


I believe the OpenGL 4.3 driver from AMD are imminent...
Wish I could comment on the sandbox.. but that last one look really nice.
Well - why is there no 580 / 680 in the table?
Las: This one includes more recent nvidia cards, but it doesn't change the picture much.

from this review
I read somewhere Nvidia simplified the compute instruction scheduler to save power, as the 600 series is more optimized for gaming than for generic GPU computing. Could also be because Nvidia runs OpenCL on top of CUDA, or maybe the Kepler drivers need(ed) optimizing, note the review is 10 months old.
from this review
I read somewhere Nvidia simplified the compute instruction scheduler to save power, as the 600 series is more optimized for gaming than for generic GPU computing. Could also be because Nvidia runs OpenCL on top of CUDA, or maybe the Kepler drivers need(ed) optimizing, note the review is 10 months old.

Last time I checked the AMD driver crashed the whole system (Win7) when a glsl shader didn't terminate.
Is that still the case?
Is that still the case?
Did you happen to have TDR disabled for some reason? Normally there's a watchdog (hund?) and if GPU doesn't finish drawing a primitive in 2.5 (iirc) then entire GPU and driver stack gets a complete reboot (formerly: BSOD).

lol 23 Million rays per second. Seems things have not changed a lot over the last decade. Current GPUs ar simply not made for incoherent memory accesses. So don't even take that graph as anything representative of a regular and real rasterization game/demo.
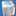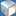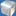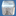
23M ray. Thats 24fps for 1280x720 for this scene (I think)

Far from rasterization efficiency, or state of the art for RT or PT...
But I dont think any CPU can match the ray per $ GPU offers.
note: I posted the chart only as a relative metric for this thread topic request.
Far from rasterization efficiency, or state of the art for RT or PT...
But I dont think any CPU can match the ray per $ GPU offers.
note: I posted the chart only as a relative metric for this thread topic request.
CPU implementations were doing around 5 million rays per second, PER CORE, back in 2007. I think CPUs are still preferred for raytracing. In the other hand, good Optix tracers can do 100 million rays per second, although they very quickly drop to 50 when doing anything beyond direct lighting.
Will see, give it another 15 years.
Will see, give it another 15 years.
Yeah but these are GPUs aimed at gaming, they aren't even optimized at all for raytracing.
I'd like to see these tests run on a Quadro or FirePro GPU. It would probably have much better results.
I'd like to see these tests run on a Quadro or FirePro GPU. It would probably have much better results.

iq: do movie studios utilize GPUs for the final render?

firstly that review / benchmark - the 680 architecture is quite different from the 580 and when that review was taken the drivers probably werent up to scratch. note that the dx11 hlsl case performs pretty well whereas the opencl is weak, which could well be because the hlsl compiler back end has had more effort put into making it work for the architecture.
ive traditionally found that nvidia tends to win on memory bandwidth scenarios and ati on pure alu. but i have to say that radeon 7970 is really, really fast (i have one, and a 570 and ive tested against a 680..), and i personally think ati won this generation. if youre working with dx11 compute, anyway. opencl seems to be lagging behind for all vendors, and obviously cuda supports some features of nv hardware that compute and cl dont expose.
as for gpu raytracing.. renderers like arion and octane are proving the power of using the gpu instead of or alongside the cpu. dunno about those 23m rays figures tho.
i guess the problem is that while raytracing is supposed to be "embarrassingly parallel", it actually isnt in the way the gpu needs. unless rays are completely coherent you hit different branches / code paths / tree paths, and parallelism within one gpu wavefront is lost, and with it performance. kepler's architecture is supposed to help with that kind of scenerio, though (if youre using cuda).
hofstee: im not really sure what youre talking about - gpus optimized for raytracing? how exactly do they optimise a gpu for raytracing? the quadros are just upclocked versions of the geforces with more memory (and different drivers?), they dont have a whole other architecture.
ive traditionally found that nvidia tends to win on memory bandwidth scenarios and ati on pure alu. but i have to say that radeon 7970 is really, really fast (i have one, and a 570 and ive tested against a 680..), and i personally think ati won this generation. if youre working with dx11 compute, anyway. opencl seems to be lagging behind for all vendors, and obviously cuda supports some features of nv hardware that compute and cl dont expose.
as for gpu raytracing.. renderers like arion and octane are proving the power of using the gpu instead of or alongside the cpu. dunno about those 23m rays figures tho.
i guess the problem is that while raytracing is supposed to be "embarrassingly parallel", it actually isnt in the way the gpu needs. unless rays are completely coherent you hit different branches / code paths / tree paths, and parallelism within one gpu wavefront is lost, and with it performance. kepler's architecture is supposed to help with that kind of scenerio, though (if youre using cuda).
hofstee: im not really sure what youre talking about - gpus optimized for raytracing? how exactly do they optimise a gpu for raytracing? the quadros are just upclocked versions of the geforces with more memory (and different drivers?), they dont have a whole other architecture.

Modern CPU are bound to the same limitations.
If you want to 'unlock' a CPU compute power you need to use SIMD, and you are then faced with the same limitations with code path bifurcation.
But Intel Knight Corners is a taste of whats to come.
We are in line to have the CPU and GPU fused (x86 / ARM) in the next 5 years.
I can see 16+ core CPU with a complete 512bit SIMD engine being the norm for HPC.
You can see this strategy emerge from AMD, nVidia & Intel.
I dont think we will get away from all the efforts maximizing ray coherence. So whats good for the GPU is good for the CPU.
If you want to 'unlock' a CPU compute power you need to use SIMD, and you are then faced with the same limitations with code path bifurcation.
But Intel Knight Corners is a taste of whats to come.
We are in line to have the CPU and GPU fused (x86 / ARM) in the next 5 years.
I can see 16+ core CPU with a complete 512bit SIMD engine being the norm for HPC.
You can see this strategy emerge from AMD, nVidia & Intel.
I dont think we will get away from all the efforts maximizing ray coherence. So whats good for the GPU is good for the CPU.
No mention of the new Caustics cards from imgtec that were announced (or launched?) in the last week or so? Ok, so they're workstation cards ($800+ I think), but they're dedicated raytracing cards, making them pretty relevant :)
The specs seem pretty good. They're quoting 70m rays / second for each chip (the higher end card has 2). I'm a lot more impressed by this, because from what I read elsewhere the chips are manufactured on an old process and are passively cooled. I.e. they're the tech equivalent of a low/mid-range GPU from a few years back.
https://www.caustic.com/series2/index.html
The specs seem pretty good. They're quoting 70m rays / second for each chip (the higher end card has 2). I'm a lot more impressed by this, because from what I read elsewhere the chips are manufactured on an old process and are passively cooled. I.e. they're the tech equivalent of a low/mid-range GPU from a few years back.
https://www.caustic.com/series2/index.html

http://glsl.heroku.com/e#6472.0
http://glsl.heroku.com/e#6474.0
Waiting for the pony-shaders...
http://glsl.heroku.com/e#6474.0
Waiting for the pony-shaders...
I've always been utterly confused with the rays per second metric!
does it mean 1 ray encompasses all the hit detection's for that pixel e.g. a path tracer might need 50 hit detection's for each ray as it traverses thru the geometry until it hits a light.
or does it mean 1 ray = 1 hit detection?
anybody enlightented about this :P
does it mean 1 ray encompasses all the hit detection's for that pixel e.g. a path tracer might need 50 hit detection's for each ray as it traverses thru the geometry until it hits a light.
or does it mean 1 ray = 1 hit detection?
anybody enlightented about this :P

some comments on all the RT confusion: ;)
@shabby: 1 ray = 1 intersection/traversal through the scene, otherwise it's usually referred to as 1 path (which is even more fuzzy though, as it depends on scene and path tracing technique(s) used)
@psonice: The cards are definetly not bad, but they put one burden onto the programmer: One has to code wavefront-style, i.e. no wild shooting of rays, anytime you want and getting the result within the same shader, etc. (although one might argue that also GPU/CPU ray tracing will get that burden in the not-so-far future, too)
@seven/iq: the luxmark stuff has to be taken with a grain of salt, as opencl is not really what nvidia recommends, so for pure RT, this is more like what one can expect: http://www.tml.tkk.fi/~timo/HPG2009/index.html
@smash: while arion and octane are definetly not bad performance-wise (where is iray there, btw? :)), i would say that brigade (but which is now getting sucked into octane more and more, who knows if this is good or bad) is state of the art when it comes to RT with "reasonable" complex shading and animation.
@shabby: 1 ray = 1 intersection/traversal through the scene, otherwise it's usually referred to as 1 path (which is even more fuzzy though, as it depends on scene and path tracing technique(s) used)
@psonice: The cards are definetly not bad, but they put one burden onto the programmer: One has to code wavefront-style, i.e. no wild shooting of rays, anytime you want and getting the result within the same shader, etc. (although one might argue that also GPU/CPU ray tracing will get that burden in the not-so-far future, too)
@seven/iq: the luxmark stuff has to be taken with a grain of salt, as opencl is not really what nvidia recommends, so for pure RT, this is more like what one can expect: http://www.tml.tkk.fi/~timo/HPG2009/index.html
@smash: while arion and octane are definetly not bad performance-wise (where is iray there, btw? :)), i would say that brigade (but which is now getting sucked into octane more and more, who knows if this is good or bad) is state of the art when it comes to RT with "reasonable" complex shading and animation.

thanks for clearing that up toxie - it makes perfect sense now.
That "Yet Faster Ray-Triangle Intersection (Using SSE4)" paper claims 143 mill hit tests/sec which appears much faster than the 70m on those cards. But as pointed out thats raw hits , not full path traversal.
Coder ray = ray hits 1 triangle
Card ray = full ray path traversal
That "Yet Faster Ray-Triangle Intersection (Using SSE4)" paper claims 143 mill hit tests/sec which appears much faster than the 70m on those cards. But as pointed out thats raw hits , not full path traversal.
Coder ray = ray hits 1 triangle
Card ray = full ray path traversal
toxie: so pretty much along the lines of raytracing in a shader, except that the card is designed for tracing rays instead of shading pixels?
It looks (from a very brief look) to be about half the performance of a fast CPU or GPU implementation. But that's still seriously fast, considering the hardware level. Hopefully we'll see a high-end part at some point, then we'll have a much better idea of what it's capable of.
It looks (from a very brief look) to be about half the performance of a fast CPU or GPU implementation. But that's still seriously fast, considering the hardware level. Hopefully we'll see a high-end part at some point, then we'll have a much better idea of what it's capable of.
@shabby: no, the "card ray" is also a "coder ray"
@psonice: kinda, but they have some serious advantages currently: a) they can handle rigid objects/animations/partial updates of their scene better (on GPU the only stuff that is -really- tracing rays fast needs a complete rebuild most of the time to get maximum hierarchy quality, i.e. this cripples your rays/second stats heavily, OR one has a crappy hierachy each frame which also cripples traversal/intersection speed)
b) the results from intersection pop out spatially coherent, i.e. better SIMD/T utilization later-on (shading/materials/textures) without resorting
and you're right, having a decent high-end board could be scary performance, although i wonder if they have some bottlenecks in their current traversal scheme that would kick in more then (i.e. not-so-linear scale with shrinking the manufacturing process/cranking up the clocks)
@psonice: kinda, but they have some serious advantages currently: a) they can handle rigid objects/animations/partial updates of their scene better (on GPU the only stuff that is -really- tracing rays fast needs a complete rebuild most of the time to get maximum hierarchy quality, i.e. this cripples your rays/second stats heavily, OR one has a crappy hierachy each frame which also cripples traversal/intersection speed)
b) the results from intersection pop out spatially coherent, i.e. better SIMD/T utilization later-on (shading/materials/textures) without resorting
and you're right, having a decent high-end board could be scary performance, although i wonder if they have some bottlenecks in their current traversal scheme that would kick in more then (i.e. not-so-linear scale with shrinking the manufacturing process/cranking up the clocks)
thanks, that clarifies it plenty - the current cards make quite a bit more sense (if they were really 1/2 the speed of a regular render, why buy the card?)
From what you've said, they make pretty much perfect sense for modelling work where you need a high quality preview but the scene is changing all the time. The caustics cards should give quite a good speedup there. Of course it's a small market... so they make the cards cheaply (using old process / low clock speed), sell them at a high price, and they get hardware out in the market without losing lots of money :)
I guess there's not really a market for any 'high end' boards yet. Hopefully what they've produced will create the market by getting the software ready, then maybe we'll see if there's any issues pushing it into the high end.
From what you've said, they make pretty much perfect sense for modelling work where you need a high quality preview but the scene is changing all the time. The caustics cards should give quite a good speedup there. Of course it's a small market... so they make the cards cheaply (using old process / low clock speed), sell them at a high price, and they get hardware out in the market without losing lots of money :)
I guess there's not really a market for any 'high end' boards yet. Hopefully what they've produced will create the market by getting the software ready, then maybe we'll see if there's any issues pushing it into the high end.
I still think compute platform like Intel MIC will be the future for production quality ray tracing.
I haven't followed closely, but if anyone going to invest into developing custom code it would be for that platform.
So I'm not sure where intel is at with Embree 2.0.
But if those guys 'settle' on a set of algorithm, they can analyse the logic and see if any portion make sense to move to silicon.
http://software.intel.com/sites/default/files/article/262143/embree-siggraph-2012-final.pdf
I haven't followed closely, but if anyone going to invest into developing custom code it would be for that platform.
So I'm not sure where intel is at with Embree 2.0.
But if those guys 'settle' on a set of algorithm, they can analyse the logic and see if any portion make sense to move to silicon.
http://software.intel.com/sites/default/files/article/262143/embree-siggraph-2012-final.pdf