
|
Space Fungus by Frigo
[nfo]
|
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|

|
|
|||||||||||||
|
popularity : 61% |
|||||||||||||
alltime top: #9233 |
|
|||||||||||||
|
||||||||||||||
added on the 2019-09-16 20:55:49 by TomCatAbaddon  |
||||||||||||||

popularity helper
comments
Good 128 byter ;) Just kidding, this looked surprisingly beautiful =)
rulez added on the 2019-09-16 21:10:45 by HellMood 
Oh god I can see forever

great!

It was super nice on the big screen.
Looks awesome! <3

should have won

My God, it's full of fungus!

Awesome.

Lovely!

Simply amazing for it's filesize!

awesome trip %)
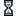
nice effect, good work!

details!

Thank you guys, I really appreciate the kind comments.
I would like to thank TomCatAbaddon, Rrrolo, and Kali for their open source demos, shaders, and presentations. Without them this demo would not be here.
I likewise included the source code, for both the ShaderToy prototype and the assembly code as well.
I would like to thank TomCatAbaddon, Rrrolo, and Kali for their open source demos, shaders, and presentations. Without them this demo would not be here.
I likewise included the source code, for both the ShaderToy prototype and the assembly code as well.
Damn it, I accidentally rated my own demo with the pig.
Nice choice of a Kali-set, Frigo :-)
When I was looking through your well commented source code and the shader code, I was thinking to myself that those kind of algoritms just 'cry' for an SSE implementation for speed and may be even size...
...so to revisit my SSE knowledge I coded an SSE version of your intro. It requires SSE level 4.1 CPU's and assembles with FlatAssembler. You can find it for download here.
Even with ESC/textmode support I'm down to 244 Bytes and a huge speed bonus. Your version would run on my laptop at around 5 FPS, the SSE version is around 13 FPS :-)
So in special code cases SSE can be benefitial for 256 Byte intros :-)
When I was looking through your well commented source code and the shader code, I was thinking to myself that those kind of algoritms just 'cry' for an SSE implementation for speed and may be even size...
...so to revisit my SSE knowledge I coded an SSE version of your intro. It requires SSE level 4.1 CPU's and assembles with FlatAssembler. You can find it for download here.
Even with ESC/textmode support I'm down to 244 Bytes and a huge speed bonus. Your version would run on my laptop at around 5 FPS, the SSE version is around 13 FPS :-)
So in special code cases SSE can be benefitial for 256 Byte intros :-)

Let the game begin!
:) FPU is in my little finger already but I really should have learn SSE
some little CPU tweaks:
- you can init bank with CWD instead of XOR DX,DX
- you can use CX for Y coord instead of BX
then you don't have to preserv BX by PUSH/POP BX pair
and you can simple mov bl,ITERATIONS instead of mov bx,ITERATIONS
some little FPU tweaks:
before:
after:
before:
after:
now 229b
:) FPU is in my little finger already but I really should have learn SSE
some little CPU tweaks:
- you can init bank with CWD instead of XOR DX,DX
- you can use CX for Y coord instead of BX
then you don't have to preserv BX by PUSH/POP BX pair
and you can simple mov bl,ITERATIONS instead of mov bx,ITERATIONS
some little FPU tweaks:
before:
Code:
fstp st0 ;frames get rid of s
fld1 ;1 frames
faddp st1,st0 ;frames +=1
after:
Code:
fdiv st0,st0
faddp st1,st0 ;frames +=1
before:
Code:
main:
...
fstp dword[si+bp] ;s frames
...
;p=(x/W-0.5, (y/H-0.5)*H/W, 0.1)
fld dword[si+16] ;0.1 s frames
mov word[si+bp],bx
fild word[si+bp] ;y-H/2 0.1 s frames
mov word[si+bp],ax
fild word[si+bp] ;x-W/2 y-H/2 0.1 s frames
fild word[si] ;W x-W/2 y-H/2 0.1 s frames
fdiv st1,st0 ;W (x-W/2)/W y-H/2 0.1 s frames
fdivp st2,st0 ;(x-W/2)/W (y-H/2)/W 0.1 s frames
;p.xy*=s
fld st3 ;s p.x p.y p.z s frames
fmul st1,st0 ;s p.x*s p.y p.z s frames
fmulp st2,st0 ;p.x*s p.y*s p.z s frames
fstp dword[si+bp] ;p.y*s p.z s frames
fstp dword[si+bp+4] ;p.z s frames
fstp dword[si+bp+8] ;s frames
after:
Code:
main:
...
fstp dword[si+bp] ;s frames
fidiv word[si] ;s/W frames
...
;p=(x/W-0.5, (y/H-0.5)*H/W, 0.1)
fld dword[si+16] ;0.1 s/W frames
fstp dword[si+bp+8] ;s/W frames
nextaxis:
mov word[si+bp],ax
fld st0 ;s/W s/W frames
fimul word[si+bp] ;p.x s/W frames
xchg ax,cx
fstp dword[si+bp] ;s/W frames
xor bp,4
jpe nextaxis
now 229b
I think the best part about it is how it gradually reveals itself - sure, common with fractals, but a good show is a good show.

To speed things up even more using the out-of-order capabilities and the multiple instruction ports of those modern CPU's I made a version with an inner loop that calculates location x and x+1 at the same time, so that there are no directly dependant instructions.
Before:
After:
...just takes a lot of bytes...now back at around 279 bytes due to the x+1 preparation and additional bytes for plotting. We can save if we use divps instead rcpps/mulps and reach almost 256 without esc/textmode.
But hey...speed is up from 13 FPS to 23 FPS (!) between those two SSE variants. So more than 4 times the fpu version. Link to the code is here. I guess those kind of lengthy speedcode optimizations would be more usefull for a 512 Byter :-)
Before:
Code:
kaliset_loop:
movaps xmm2,xmm0 ;d = old p
dpps xmm2,xmm2,01111111b ;d = dot(p,p) of first 3 floats and put result in all 4 floats
andps xmm0,xmm7 ;p = abs(p) by mask
rcpps xmm2,xmm2 ;reverse div+multiply is faster than divps, accuracy seems okay
mulps xmm0,xmm2 ;p = abs(p)/dot(p,p)
dec bx ;reordered, may be saves some cycles
subps xmm0,xmm6 ;p = abs(p)/dot(p,p)-(1,1,0.1)*m
addps xmm1,xmm0 ;c+=p
jnz kaliset_loop
After:
Code:
kaliset_loop:
movaps xmm2,xmm0 ;d1 = old p1
movaps xmm5,xmm3 ;d2 = old p2
dpps xmm2,xmm2,01111111b ;d1 = dot(p1,p1) of first 3 floats and put result in all 4 floats
andps xmm0,xmm7 ;abs(p1)
dpps xmm5,xmm5,01111111b ;d2 = dot(p2,p2)
andps xmm3,xmm7 ;abs(p2)
rcpps xmm2,xmm2 ;reverse div+multiply is faster than divps, accuracy seems okay
dec bx ;reordered, may be saves some cycles
rcpps xmm5,xmm5
mulps xmm0,xmm2 ;p1 = abs(p1)/dot(p1,p1)
mulps xmm3,xmm5 ;p2 = abs(p2)/dot(p2,p2)
subps xmm0,xmm6 ;p1 = abs(p1)/dot(p1,p1)-(1,1,0.1)*m
subps xmm3,xmm6 ;p2 = abs(p2)/dot(p2,p2)-(1,1,0.1)*m
addps xmm1,xmm0 ;c1+=p1
addps xmm4,xmm3 ;c2+=p2
jnz kaliset_loop
...just takes a lot of bytes...now back at around 279 bytes due to the x+1 preparation and additional bytes for plotting. We can save if we use divps instead rcpps/mulps and reach almost 256 without esc/textmode.
But hey...speed is up from 13 FPS to 23 FPS (!) between those two SSE variants. So more than 4 times the fpu version. Link to the code is here. I guess those kind of lengthy speedcode optimizations would be more usefull for a 512 Byter :-)
I don't really understand why is this much faster. You have to do the same amount of operations. Maybe if you could compute 4 pixels at once, and use MOVAPS [ES:DI],XMM0 instead of STOSD , then you can gain some more speed.
btw if you put PUSH AX after INC AX then you can save one byte, because you need just one more INC AX (not two) at the end of the loop.
btw if you put PUSH AX after INC AX then you can save one byte, because you need just one more INC AX (not two) at the end of the loop.
@Tomcat: To understand that you have to look at the architecture of CPU's. For example Intel Skylake. You see that internally a CPU has parallel execution ports for different instructions. The sheduler tries to keep those ports/units as occupied as possible.
So. e.g. a MOVAPS can be executed in port 0,1 and 5. A MULPS in port 0 and 1, a DIVPS only in port 0. So if consecutive instructions are independant (don't need the previous result or modify registers of the previous) those instructions can be executed in parallel in those ports. So also reordering code sometimes helps. It's a bit of try and error.
What instruction runs in which ports can be found in Agner's manuals here.
There are even more internal helpers in modern CPU's to speed up execution time, if I remember e.g. there are internally much more registers and they can be renamed to speed up things. But I'm not really an expert on those things.
Yes, may be replacing the STOSD would also, didn't try that. Calculating 4 pixels though would be a lot of overhead I guess...
So. e.g. a MOVAPS can be executed in port 0,1 and 5. A MULPS in port 0 and 1, a DIVPS only in port 0. So if consecutive instructions are independant (don't need the previous result or modify registers of the previous) those instructions can be executed in parallel in those ports. So also reordering code sometimes helps. It's a bit of try and error.
What instruction runs in which ports can be found in Agner's manuals here.
There are even more internal helpers in modern CPU's to speed up execution time, if I remember e.g. there are internally much more registers and they can be renamed to speed up things. But I'm not really an expert on those things.
Yes, may be replacing the STOSD would also, didn't try that. Calculating 4 pixels though would be a lot of overhead I guess...
I couldn't let this go, so after extensive constants shrink, optimizing far jumps and some hints from TomCat and his FPU shrink I'm down to 252 for the divps version and 258 for the rcpps one including exit/textmode support :-)
Framerate is still 23 FPS for rcpps and about 21 FPS for dvips. You can find it here
Framerate is still 23 FPS for rcpps and about 21 FPS for dvips. You can find it here
Nice psykaleidoscopic show!

128bit write to vidmem instead of 32bit... just for speed compare... download
Not restoring textmode is not a deal if you use VolkovCommander, otherwise type command: mode 80
Not restoring textmode is not a deal if you use VolkovCommander, otherwise type command: mode 80
128bit write to vidmem brings another speed improvement: from previously 23 FPS to 30 FPS on my laptop :-)
...with the findings to reduce the overhead for the clamping stuff I added double pixel plot by MOVQ which resulted in 26 FPS for rcpps while still keeping the file size (rcpps at 254 Bytes, divps at 248 Bytes) :-) Find the code at the same link as above from my previous post.
Very cool!

Need a video since twitch says "Sorry. Unless you’ve got a time machine, that content is unavailable."

{kind=link}
submit changes
if this prod is a fake, some info is false or the download link is broken,
do not post about it in the comments, it will get lost.
instead, click here !